






服务热线

站点名称:AniPortrait
所属分类:AI视频生成
相关标签:AI视频工具 AniPortrait AniPortrait肖像动画 肖像动画 虚拟现实动画工具 逼真表情动画 逼真表情动画生成工具 音频肖像动画合成 音频驱动动画
官方网址:https://arxiv.org/html/2403.17694v1
访问官网
站点介绍
AniPortrait是一个由腾讯推出的音频驱动的肖像动画合成框架,能够根据音频和静态人脸图片生成逼真的动态视频。它利用音频文件驱动,生成逼真的肖像动画。用户可以通过提供一个音频文件和一张参考的肖像图片,让AniPortrait根据音频中的语音和声音的节奏来动态地生成说话或表情变化的肖像动画。此外,它还支持面部再现功能,通过分析给定视频中的面部表情和动作,可以在另一张参考肖像上再现相同的表情和动作。
AniPortrait包含两个主要模块:Audio2Lmk和Lmk2Video。Audio2Lmk模块从音频输入中提取一系列landmarks,捕捉复杂的面部表情和嘴唇动作;而Lmk2Video模块则利用这个具有里程碑意义的序列来生成具有时间稳定性的高质量人像视频。
项目地址:
文章地址:https://arxiv.org/abs/2403.17694
项目代码:https://github.com/Zejun-Yang/AniPortrait
 AniPortrait的功能特点
AniPortrait的功能特点AniPortrait包含两个模块,即Audio2Lmk和Lmk2Video。Audio2Lmk旨在从音频输入中提取一系列landmarks,捕捉复杂的面部表情和嘴唇动作。Lmk2Video利用这个具有里程碑意义的序列来生成具有时间稳定性的高质量人像视频。整体框架如下:
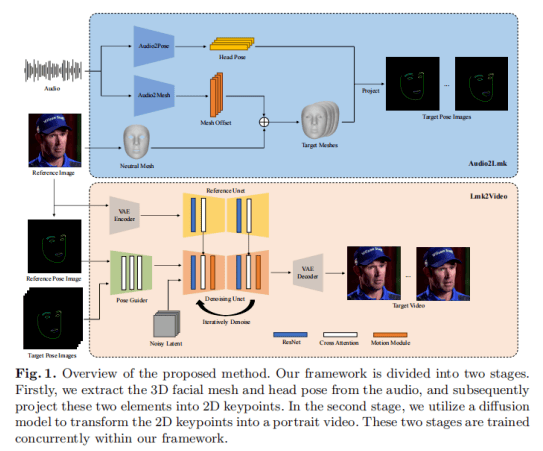
AniPortrait整体框架
(第一阶段从音频中提取三维面部网格和头部姿态,然后将这两个元素投影到二维关键点上,第二阶段利用扩散模型将2D关键点转换为人像视频)
2.1 Audio2Lmk
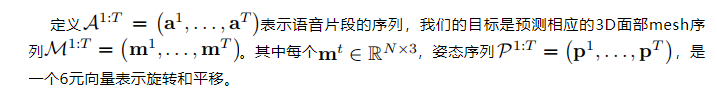
同时使用预训练的wav2vec来提取音频特征。wav2vec该模型具有高度的泛化性,能够准确地识别语音和语调,这对于生成逼真的面部动画起着关键作用。通过利用所获得的鲁棒语音特征,可以有效地采用由两个fc层组成的简单架构将这些特征转换为3D面部网格。这种简单的设计不仅保证了准确性,而且提高了推理过程的效率。
在将音频转换为姿态的任务中,使用相同的wav2vec网络作为主干,但是不与audio-to-mesh共享权重。这是因为姿势与音频中的节奏和音调联系更紧密,这与音频到网格任务的重点不同。为了考虑先前状态的影响,我们使用transformer解码器来解码姿势序列。在此过程中,音频特征通过交叉注意机制集成到解码器中,上述两个模块使用简单的L1损失来训练
在获得网格和姿态序列后,使用透视投影将它们转换为二维面部landmarks序列。这些landmarks随后被用作下一阶段的输入信号。
2.2 Lmk2Video

与AnimateAnyone不同的是,Lmk2Video增强了poseguide设计的复杂性。原始版本仅包含几个卷积层,之后landmark特征与骨干输入层的潜在特征合并。实验发现,这种基本的设计在捕捉嘴唇的复杂运动方面是不够的。因此,最终采用ControlNet的多尺度策略,将相应尺度的landmark特征整合到主干的不同块中。
此外引入了一个额外的改进:包含参考图像的landmark作为额外的输入。PoseGuider的交叉注意模块促进了参考landmark和每帧目标landmark之间的交互。这个过程为网络提供了额外的线索来理解面部landmark和外观之间的相关性,从而帮助生成具有更精确运动的肖像动画。
AniPortrait效果展示用户提供一个音频文件和一张参考的肖像图片实现动画生成。
https://img.pidoutv.com/wp-content/uploads/2024/03/316711426-51a502d9-1ce2-48d2-afbe-767a0b9b9166.mp4用户提供一段视频,实现在新的肖像上复现视频中人物的面部表情和动作。
https://img.pidoutv.com/wp-content/uploads/2024/03/316711084-849fce22-0db1-4257-a75f-a5dc655e6b9e.mp4如果你经常无法打开"AniPortrait",可能有以下三种原因。这里有一些解决方案:
如还有疑问,可在线留言,着急的话也可以通微信联系管理员。
1、本站所提供的 "AniPortrait" 站点内容均来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由本站实际控制。
2、在2024-09-06 17:55:31收录时,该站点的内容都属于合规合法,后期该站点如出现违规,可以直接联系管理员进行删除,本站不承担任何责任。

相似站点
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 关于我们 | 免责声明 | 联系QQ:896047788 微信:LiuLian-8090 请注明来意! Copyright © 2026 慧呗科技 All Rights Reserved. 苏ICP备2022019151号 XML地图
