








服务热线

站点介绍
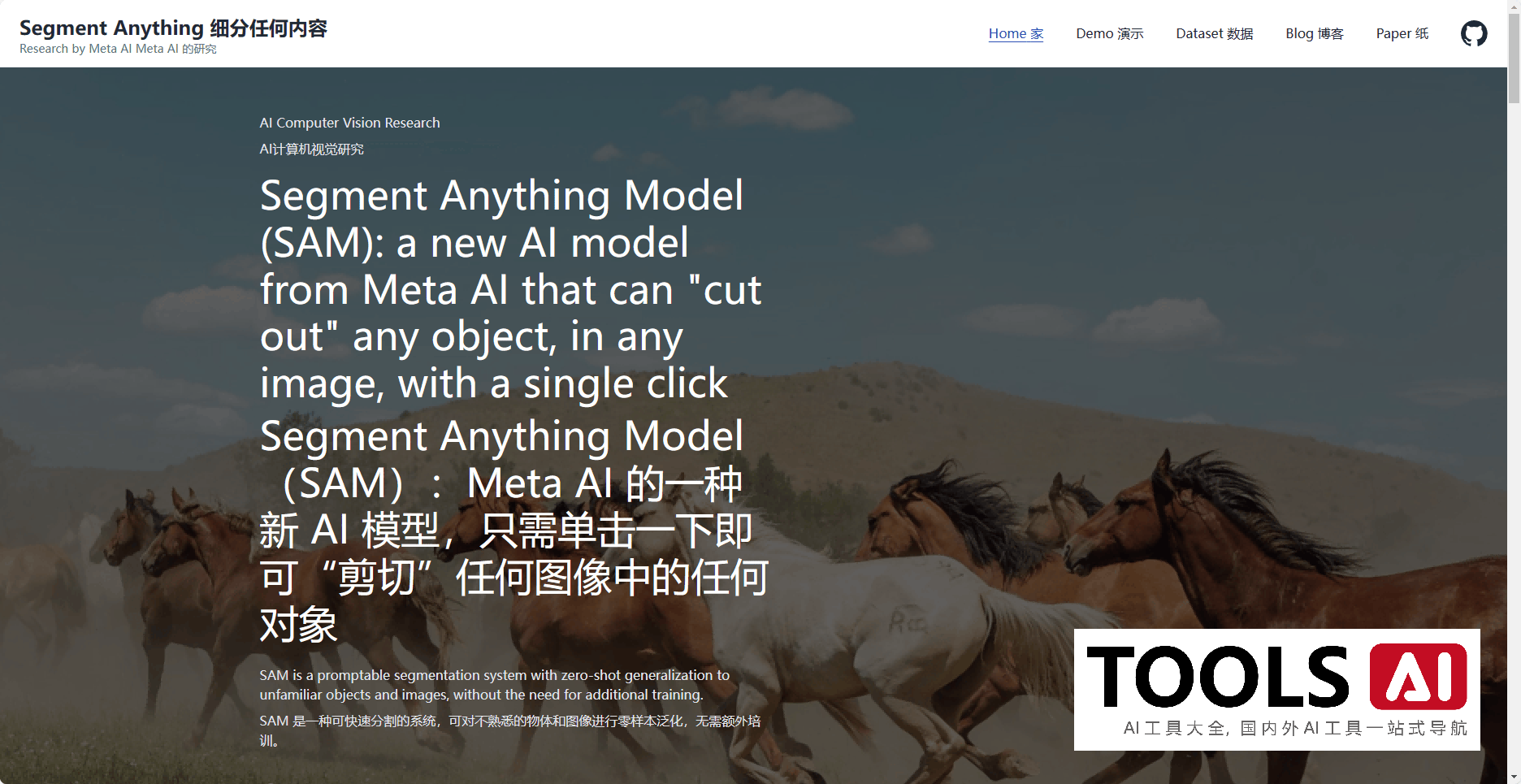
Segment Anything是一个基于深度学习的图像分割模型,它可以根据用户的输入提示(如点或框)生成高质量的物体遮罩。它可以用于为图像中的任何物体生成遮罩,无论是常见的物体(如人、车、猫等),还是罕见的物体(如火箭、恐龙、魔法棒等)。它的特点是具有强大的零样本性能,即它可以在没有见过的类别上进行分割,而不需要额外的训练数据。它的另一个优点是具有快速的推理速度,即它可以在几秒钟内处理一张图像,而不需要显卡或云计算资源。
Segment Anything是由澳大利亚国立大学的研究团队开发的,他们在一个包含1100万张图像和10亿个遮罩的大规模数据集上对模型进行了训练。他们还在多个公开的分割数据集上对模型进行了评估,证明了它的优越性能。他们将Segment Anything的代码、模型检查点和示例笔记本都发布在了GitHub上,供感兴趣的用户和研究者下载和使用。他们还提供了一个网页版的演示,让用户可以直接在浏览器中尝试Segment Anything的功能。此外,他们还将他们的数据集开源,以促进图像分割领域的进一步研究和创新。Segment Anything是一个具有前瞻性和实用性的图像分割模型,它为用户提供了一个简单而强大的工具,可以用于各种图像处理和分析的应用场景。
Segment Anything的功能特点1、支持多种输入方式:SA支持prompt输入,包括点、框、mask、文本等,可以满足各种不同的分割需求。
2、自动识别并分割图像:SA可以自动识别哪些图像像素属于一个对象,并且对图像中各个对象进行自动风格等,可广泛用于分析科学图像、编辑照片等。
3、标注功能强大:官方demo支持交互式标注,可以通过画框、鼠标点击来获取分割的区域,此外还可以一键分割一切,轻轻点一下,将分割结果实时展示出来。对于不太确定的类别提供了多个有效的区域。
4、多元化交互:支持三维SAM模型的输出结果可以作为其他AI的输入,比如下图的视频里不断被追踪分割椅子,进而提取出椅子的特征,可以生成椅子的三维模型。
5、无需fine-tune即可对图中任何物体进行分割:SAM模型无需fine-tune即可对图中任何物体进行分割,且能通过文本提示分割图像,效果可与有监督学习媲美。
6、标注功能的自我提升:用先交互后自动的方式标注了数以十亿记的图片,实现了标注功能的自我提升。
 Segment Anything的技术原理
Segment Anything的技术原理Segment Anything的技术原理是基于深度学习的图像分割技术,它的目标是将图像中的每个像素都分配一个类别标签,从而实现对图像的全局理解和分割。具体来说,Segment Anything的实现过程包括以下几个步骤:
Segment Anything的特点是它可以根据用户的输入提示(如点、框、掩码或文本)生成高质量的物体遮罩,无需额外的训练数据。它可以用于为图像中的任何物体生成遮罩,无论是常见的物体还是罕见的物体,展现了强大的零样本泛化能力。它可以处理模糊或不明确的提示,返回多个可能的分割结果,并给出相应的置信度评分。它具有快速的推理速度,可以在几秒钟内处理一张图像,而不需要显卡或云计算资源。它在一个包含1100万张图像和10亿个遮罩的大规模数据集上进行了训练,覆盖了多种场景和类别。
Segment Anything的模型架构由三个主要部分组成:提示编码器、图像编码器和掩码解码器。提示编码器将用户的输入提示转换为模型可以理解的形式,图像编码器提取图像的特征表征,掩码解码器将提示表征和图像表征结合起来,预测分割掩码。Segment Anything还利用了CLIP模型,使其能够理解和关联图像与文本提示,从而提升模型对图像内容的理解和分割能力。
Segment Anything的发展历程1、2023年4月,Meta AI Research团队在arXiv上发布了《Segment Anything》的论文,介绍了一个新的图像分割任务、模型和数据集。该任务的目标是根据用户的输入提示(如点、框、掩码或文本)生成高质量的物体遮罩,无需额外的训练数据。该模型的设计和训练是灵活的,因此它可以将零样本迁移至新的图像分布和任务。该数据集是迄今为止最大的分割数据集,在11M许可和尊重隐私的图像上有超过1亿个遮罩。
2、2023年5月,Meta AI Research团队在GitHub上开源了Segment Anything的代码、模型检查点和示例笔记本,供感兴趣的用户和研究者下载和使用。他们还提供了一个网页版的演示,让用户可以直接在浏览器中尝试Segment Anything的功能。
3、2023年6月,Segment Anything受到了广泛的关注和应用,许多研究者和开发者利用它来解决各种图像分割的问题,例如遥感图像分割4,可控图像字幕生成,音频-视觉定位和分割等。Segment Anything也被认为是计算机视觉领域的一个里程碑,为图像分割领域的进一步研究和创新提供了强大的基础模型。
如果你经常无法打开"Segment Anything",可能有以下三种原因。这里有一些解决方案:
如还有疑问,可在线留言,着急的话也可以通微信联系管理员。
1、本站所提供的 "Segment Anything" 站点内容均来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由本站实际控制。
2、在2024-09-03 12:12:55收录时,该站点的内容都属于合规合法,后期该站点如出现违规,可以直接联系管理员进行删除,本站不承担任何责任。

相似站点
本站收录的网站若侵害到您的利益,请联系我们删除处理!| 关于我们 | 免责声明 | 联系QQ:896047788 微信:LiuLian-8090 请注明来意! Copyright © 2026 慧呗科技 All Rights Reserved. 苏ICP备2022019151号 XML地图
